

what 4 characters do all punycodes start with?
Welcome to solsarin site ,Keep reading and find the answer of “what 4 characters do all punycodes start with? ”.
Stay with us.
Thank you for your support.
What is Punycode?
Punycode is a special encoding used to convert Unicode characters to ASCII, which is a smaller, restricted character set. It is used to encode internationalized domain names (IDN).
Punycode is an encoding standard developed for use with internationalized domain names. It allows for the encoding and representation of Unicode characters for use in hostname resolution that only supports ASCII (American Standard Code for Information Interchange) characters. This means that, for example, a domain name can be comprised of Chinese characters. Punycode then encodes those characters and makes them referable in an ASCII format.
As Unicode represents more than just international character sets, Punycode can also be used to allow for hostnames that use emojis. This is not a widely supported standard, so there is only a limited subset of top-level domains that support emojis in domain names.
Background of Punycodes
The technology that powers the internet stretches as far back as the 1960s and was developed primarily by Americans. It is because of this that ASCII historically became the default encoding standard for many computers and servers. ASCII was limited to 128 characters, which were comprised mainly of the Latin alphabet, numbers, and punctuation marks.
ASCII offered no means of encoding characters from other writing systems, like Kanji, Hangul, or Cyrillic. This provided a barrier to entry for many who cannot read the Latin alphabet and meant that companies in those markets could not use truly localized domain names.
Unicode was an encoding system developed to be expandable and cater to as many different characters as possible. ASCII is very rarely used today, but a lot of old software and hardware still runs on ASCII encoding. In order to bridge the gap between modern systems using Unicode and older systems using ASCII, Punycode was created.
Examples of Punycodes
Punycode is useful for processing internationalized domain names. As an example, Korea uses its own character system called Hangul. Hangul characters cannot be properly encoded using ASCII, so Punycode takes strings encoded with Unicode and converts them into something readable (and resolvable) using ASCII.
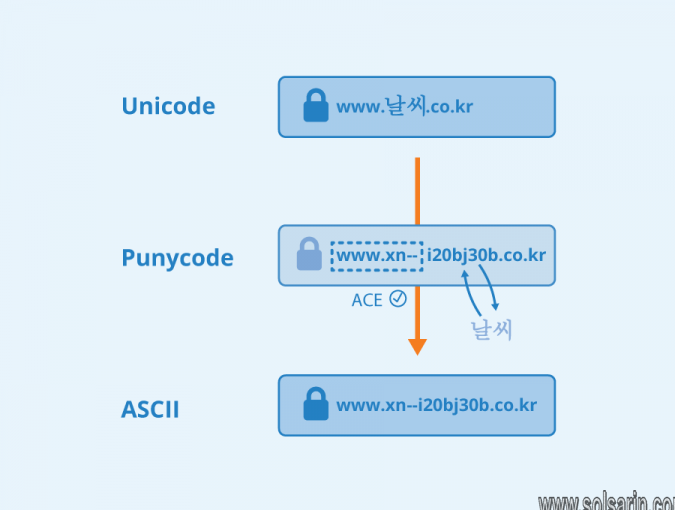
Before Punycode, companies and services operating in markets like Korea would have to adapt their brands to fit the ASCII restrictions. For example, ‘날씨 ‘ means ‘weather’ in Korean. A website would have to change its domain name to something like ‘www.weather.co.kr’. With Punycode, they can use a domain name like ‘www.날씨.co.kr’ instead, which allows brands to use their proper identities and services to be truly localized for markets that do not natively use the Latin alphabet. Punycode support also works for top-level domains, so it is possible to have internet hostnames composed entirely of non-ASCII characters that are resolvable on ASCII systems with Punycode.
For the string ‘날씨’, Punycode would convert this to ‘xn--i20bj30b’. This is a unique string that allows ASCII systems to read and interpret a string using characters outside of the ASCII standard. ASCII systems will interpret the URL ‘www.날씨.co.kr’ as ‘www.xn--i20bj30b.co.kr’. It is worth noting that most browsers will display the Punycode result in their address bar to prevent phishing attacks.
Punycode phishing attacks can happen when someone registers a domain name using a Punycode encoded string. Certain Punycode domain strings can be bought that, when interpreted, look very similar to domain names of big brands, but actually swap out a single character with a visually similar character from another character set, making it virtually undetectable.
How does Punycode work?
Punycode works as an instance of the boot string algorithm. The boot string algorithm allows for the representation of an arbitrary set of characters for use within a limited set of characters.
This is done by interpreting any string passed to it and analyzing it for non-ASCII characters. Punycode then goes through a number of steps to create a string that is usable on ASCII systems.
Firstly, all characters are normalized by converting them into lowercase where applicable. Then, the characters are searched for ASCII compatibility. Any characters found that exist within the ASCII character set are ignored; however, non-standard ASCII characters are removed from within the text and a hyphen is placed at the end of the string.
If non-standard characters are found, the prefix ‘xn--‘ is added to the string. This signifies that the string contains ACE (ASCII Compatible Encoding) and that the hyphen appended should be interpreted using Punycode instead of as part of the string itself.
Punycode then analyses the non-ASCII characters and appends a string of characters to the hyphen that uses ASCII characters to dictate which characters should be represented and where they should be placed within the string. It does this while ensuring that the end result does not exceed the 63-character limit.
An Imperfect Industry Standard of punycode
Many years ago, the Internet Corporation for Assigned Names and Numbers (ICANN) allowed non-ASCII (Unicode) characters to be included in web domains. It didn’t take long for them to realise that this decision was going to cause problems. Certain characters from different languages can be confused for Unicode, since they look the same when displayed in a browser. This could be used as a tool by cyber criminals to spoof URLs and target unsuspecting victims.
To counteract the issue, ICANN developed ‘Punycode’ as a way of specifying actual domain registrations by representing Unicode within the limited character subset of ASCII used for internet host names. The idea was that browsers would first read the Punycode URL and then transform it into displayable Unicode characters inside the browser.
However, just like with Unicode, Punycode could also hide phishing attempts using characters found in different languages. To combat this, Web browser vendors introduced add-on filters to render URLs as Punycode, instead of Unicode, if they contained characters from different languages.
Everyone thought this would stop URL substitution, however, a security researcher called Xudong Zheng managed to recently find a glitch in the matrix.
Punycode Problems
By default, many web browsers use Punycode encoding to represent unicode characters in the URL to defend against Homograph phishing attacks (where the website address looks legitimate, but is not, because a character or characters have been replaced deceptively with Unicode characters). For example, the Chinese domain “短.co” is represented in Punycode as “xn--s7y.co” and the German city of “München” becomes the Punycode “xn--mnchen-3ya” because the letter ü is not available in English.
Note: You can convert text on a site like Punycoder to see how other names are converted.
According to Zheng, the loophole means that if someone chooses a domain name where all characters are from a single foreign language character set, then browsers will render it in that language, rather than in Punycode format. This is dangerous when all of the characters selected from the foreign character set resemble the characters of the targeted domain, as they will appear to be identical when rendered in browsers.
There are quite a few Unicode characters represented in alphabets such as Greek, Cyrillic, and Armenian, which look almost identical to Latin letters at a glance, but are treated very differently by computers when resolving the different web addresses. For example, Cyrillic “а” (U+0430) and Latin “a” (U+0041) are both treated differently by browsers, but are displayed as “a” in the browser address.
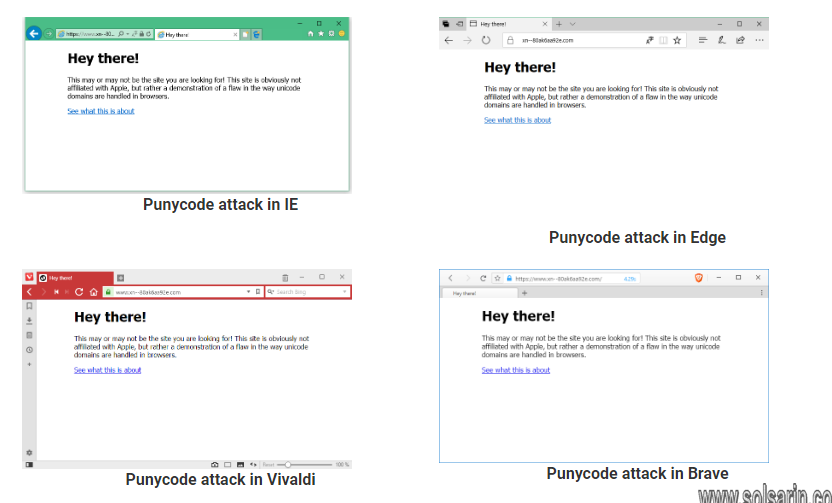
Zheng registered the domain “xn--80ak6aa92e.com”, a Cyrillic domain name. Because he used the Cyrillic “a” rather than the ASCII “a”, some browser defenses failed and displayed the URL as “аррӏе.com” when converted back from Punycode to “Russian” text.
Note: The ‘xn’ prefix is known as an ‘ASCII compatible encoding’ prefix, which indicates that the browser uses ‘Punycode’ encoding to denote Unicode characters.
Apple Safari, Microsoft Edge and Internet Explorer don’t fall for the trick domain, and simply display it as plain old xn--80ak6aa92e.com (provided your system settings don’t include any Cyrillic languages).



